05、数组
思考:为什么很多编程语言中数组都是从 0 开始编号?
什么是数组?
一种线性表数据结构,用一组连续的内存空间存储一组相同类型的数据。
线性表?
线性表:数据排成像一条线一样的结构。数据只有前、向两个方向。
常见的有:数组、链表、队列、栈等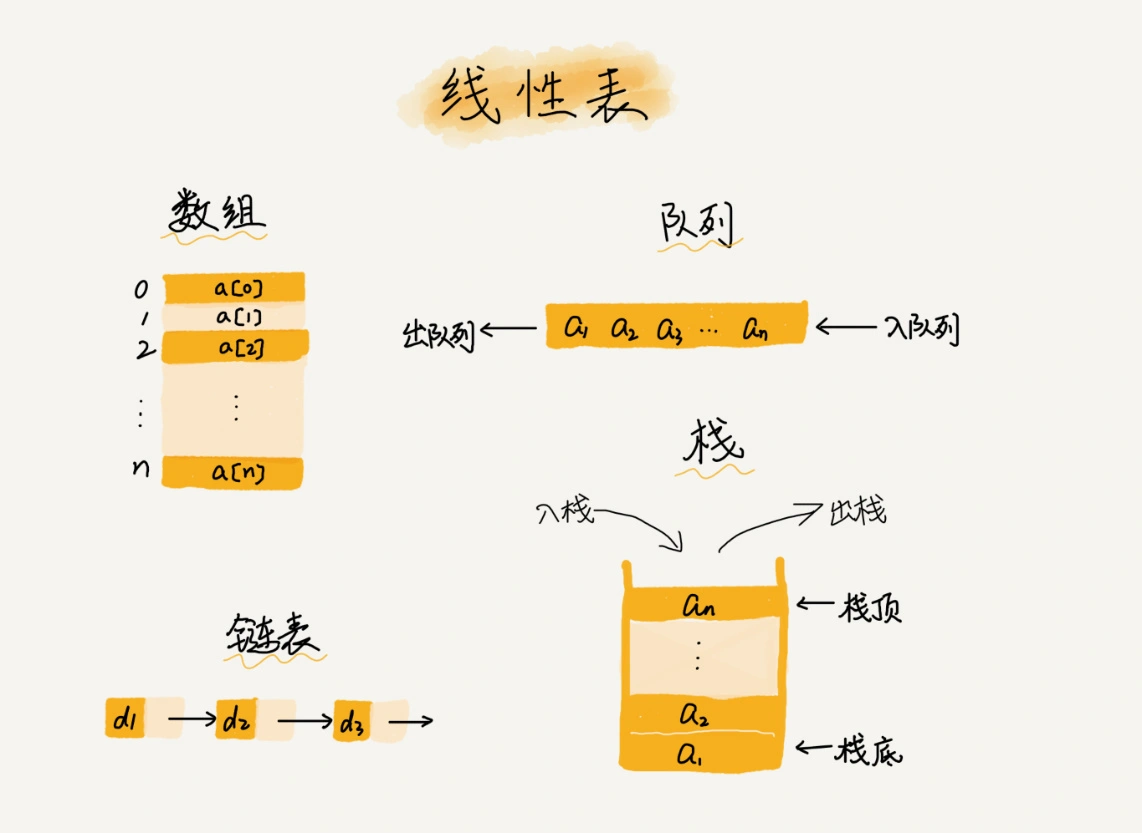
非线性表?
数据关系不是简单的前后了。
常见的有:图、二叉树等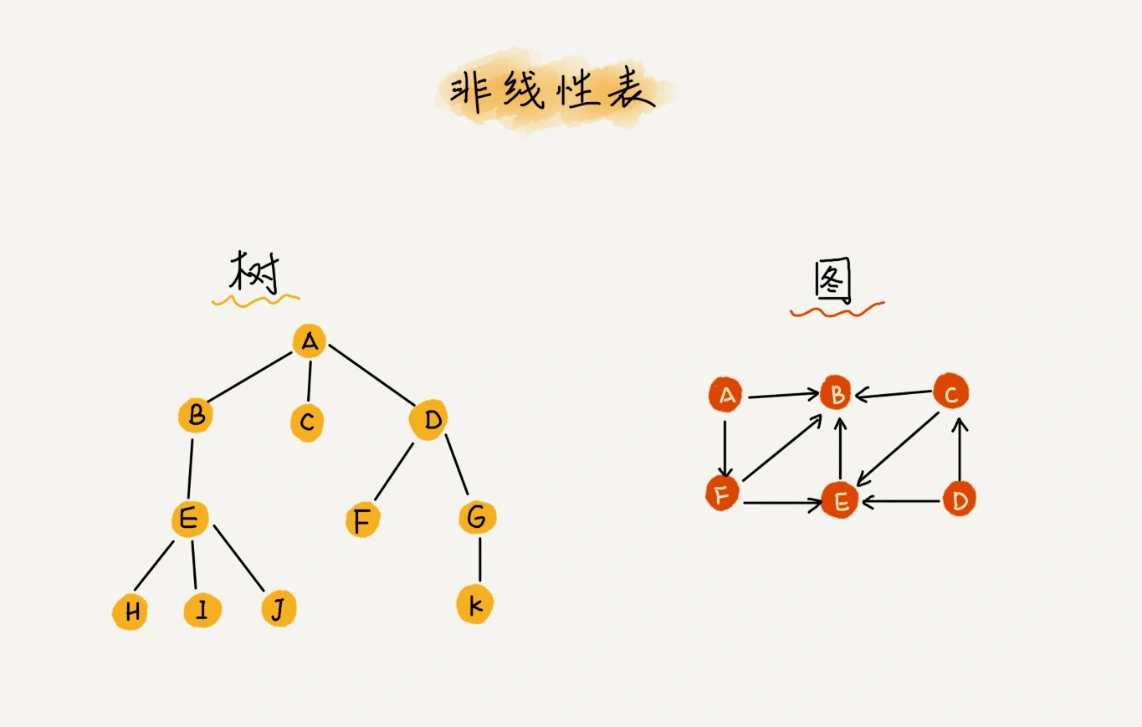
连续内存空间和相同类型?
存储的必须是空间是紧挨着的,并且每个元素的类型一样。
如果申请 10M 大小的数组,如果内存中没有连续的则申请失败,就算剩余空间大于 10 M
这也是数组能通过任意下标直接访问数组元素的原因。但同样也限制了数组的增删改查,使其操作更低效。
举例:下标随机访问的逻辑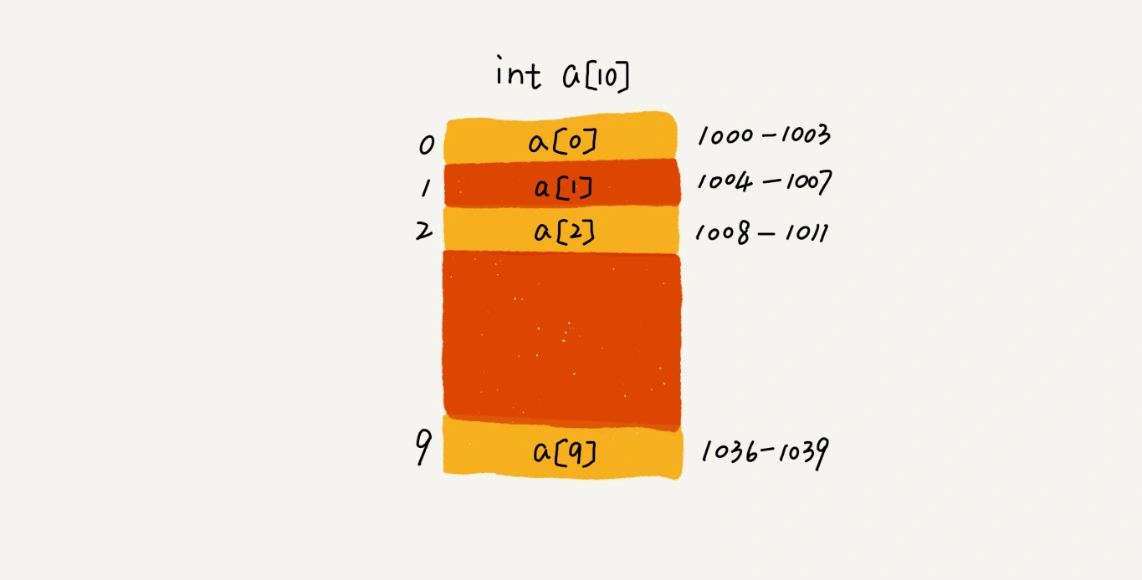
寻址公式:a[i]_address = base_address + i * data_type_size
插入操作为什么低效?
举例,数组长度为 n,若要在 k 插入一个数据,则为了保持连续性,则需要将 k~n 都往后移动一位。
若 k 为 1,则插入时间复杂度为 O(n ),若 k 为末尾,则不需要移动插入时间复杂度为 O(1),平均时间复杂度为 O(n)=(1+2+3…+n)/n
那如何高效的插入?
若被插入的数据挪到末尾,空出位置,则插入的时间复杂度为 O(1)
比如:arr = [a, d, c, d, e],在 3 插入 f,则 arr[5] = a[3],a[3] = f
同理删除操作也是如此,删除后为了连续性,需要后面的往前移动一位.
解答:
从寻址公式可以看出来:a[i]_address = base_address + i * data_type_size
若开始下标为 0,a[0] 可以直接代表“偏移量”为 0
若开始下标为 1,a[0] 则代表“偏移量”为 1 - 1 的,寻址公式改为**a[i]_address = base_address + (i-1) * data_type_size**
对比来说:会多一层计算,所以从 0 开始可以减少不必要的计算
从编程发展来说,C 语言用的是 0,其他语言效仿,慢慢大家变成从零开始
数组与链表的区别
数组要求的是连续的内存空间,而链表不要求。
数组适合随机下标访问,时间复杂度为 O(1);而链表适合插入、删除,时间复杂度为 O(1)
课后问题
二维数组的内存寻址公式是怎样的呢?
对应 m n 的二维数组
a[i][j]_address = base_address + (i n + j) * data_type_size
额外补充
JS 的基础类型所占用内存大小
undefined:不占用内存
null:不占用内存
boolean:占 1 字节
string:一个字符占 2 字节
number:8 字节
JS 里面的数组特点:
- 不需要限制相同类型;
- 可以动态扩容
- 越界不会报错,是返回 undefined