20、散列表(下)
思考:为什么散列表和链表经常会一起使用?
主要内容
可以发现散列表与链表经常一起出现。
LRU 缓存淘汰算法
前面[这节](https://www.yuque.com/u53094/vd58kv/twuqfxon23bi1473?singleDoc# 《06 | 链表(上)》)讲了 LRU 缓存淘汰算法的实现:采用链表,最晚访问的放到链表尾部,当插入时,若是新访问的放到尾部,若位置不够则删除头部的,若是访问已有的则找到它然后放到尾部去。
整体时间复杂度为 O(n),删除、插入的是 O(1),但查找需要用 O(n)
但如果使用链表结合散列表时,可以为 O(1),结构如下: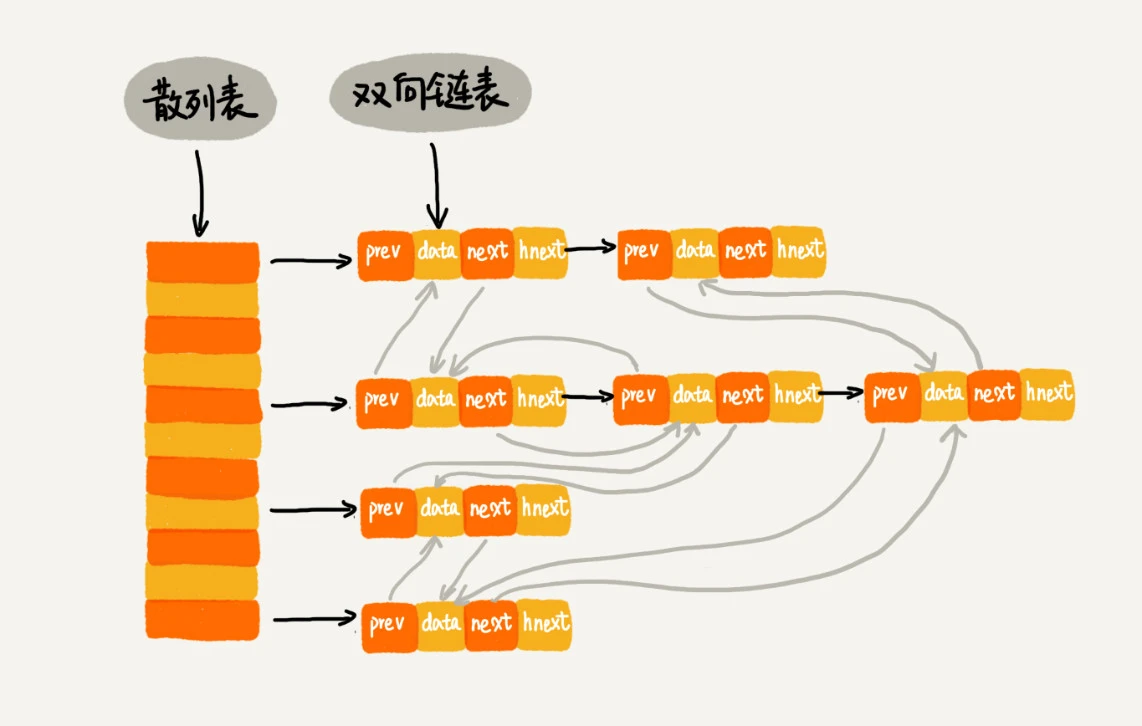
使用双向链表和散列表
prev、next 用来形成双向链表
hnext 用来形成单链表(用来解决散列冲突的链表)
Redis 有序集合
前面[这节](https://www.yuque.com/u53094/vd58kv/kfz92fee6k217wes?singleDoc# 《17 | 跳表》)讲了 Redis 有序集合的实现是通过跳表,但删除、查询就很慢。
所以又以键值构建一个散列表,这样按照 key 来删除、查找一个成员对象的时间复杂度就变成了 O(1)。
实现原理跟第一个一样。
Java LinkedHashMap
它是通过散列表和链表组合在一起实现的。还支持 LRU 算法,实现原理跟第一个一样。
解答思考
思考:为什么散列表和链表经常会一起使用?
解答:因为可以互相弥补,使得效率更高效。散列表虽然支持高效的增删查,但它本身存储的数据是经过散列函数打散的,不支持顺序查找,除非拷贝到新数组然后排序查找。但结合链表后,就可以弥补无法顺序查找的问题了。
新的思考
假设猎聘网有 10 万名猎头,每个猎头都可以通过做任务(比如发布职位)来积累积分,然后通过积分来下载简历。假设你是猎聘网的一名工程师,如何在内存中存储这 10 万个猎头 ID 和积分信息,让它能够支持这样几个操作:
- 根据猎头的 ID 快速查找、删除、更新这个猎头的积分信息;
- 查找积分在某个区间的猎头 ID 列表,比如[200, 500]
- 查找按照积分从小到大排名在第 x 位到第 y 位之间的猎头 ID 列表。
解答:
关键信息:id、score(积分)
以 score 构建跳表,实现[操作 2]
以 id 为 key 构建散列表,存储 score,实现[操作 1]